 |
TOP>活動記録>講演会>第193回 | 一覧 | 次回 | 前回 | 戻る |
 |
||||
 |
|
|
|
|
第193回 講演会(2001.7.1 開催)
|
||||
|
1.過去の日本語の起源探求
|
|
清水義範著 小説『序文』 以下のような類似の言葉292例をあげて「英語の起源は日本語だ」と主張する |
| ・ | name(ネーム) | namae(名前) |
| ・ | owe (負う | ou(負う) |
| ・ | kill(殺す) | kiru(斬る) |
| ・ | battle(戦い) | batoru(場取る) |
| ・ | boy(少年) | boya(坊や) |
|
実は、これはジョークで、『序文』はパロディー小説です。 しかし、笑ってはいられない。 明治以後の日本語の起源論のほとんどは基本的には『序文』と同じ方法。 |
|
琉球大学教授城間正雄氏 ・「日本民族形成の一視点 日本語と印欧語の関係の考察」 「火」と「fire」、「新(にい)」と「new」などの関係を考察。 「『新』についてのヨーロッパ諸語と日本語の関係は明白である」としている。 |
|
安田徳太郎博士 ・「万葉集の謎」 「万葉時代の日本語がヒマラヤの谷に住むレプチャ人によって語られている。」 「万葉集の歌のほとんどがレプチャ語で解読できる。」 |
|
大野晋氏 ・「日本語の起源」 「縄文時代中頃にタミル語が日本に伝わった。」とする。 日本語とタミル語との、意味と形の似た言葉を列挙することに終始している。 |
|
いずれも、日本語と他の言語とのあいだで意味と発音の似ている言葉が多数あり、こんなに
たくさんあるのだから、日本語と関係があるはずだ。としている。 どの言語でも、何万という単語を持つ。 人間が発音し、聞き分けられる音は、せいぜい数十種類である。 そのため、世界の任意の言語を選ぶとき、偶然、意味と音 (形)とが似ている単語を、2〜300は探し出すことができる。 学者は、みずからとりあげた二言語が、世界の任意の二言語よりも、特に関係が密接であることを「客観的」に示さなければならない。 |
|
2.客観的語彙比較の方法
|
|
統計学を活用して語彙比較をに行うことにより、数字による表現が可能となり、客観的な判断ができるようになる。また、誤りもはっきりする。 たとえば、つぎのような方法で比較を行う。 |
|
|
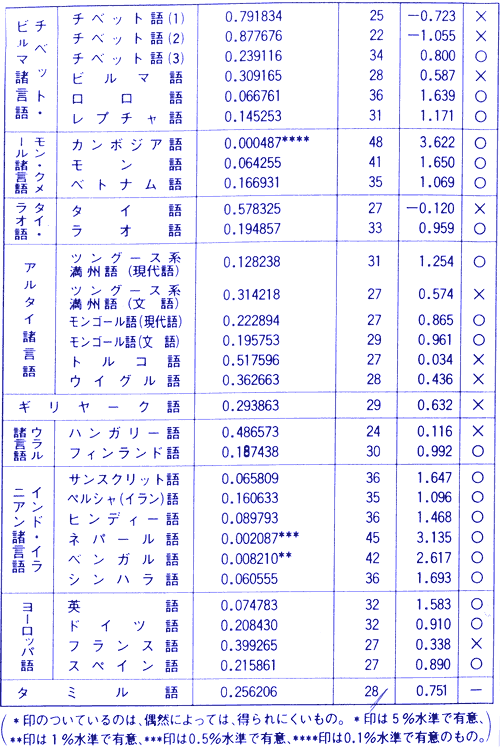
3.分析結果
|
いくつかの言語と上古日本語(奈良時代の日本語)とについて、関連性を分析した結果はつぎのとうり。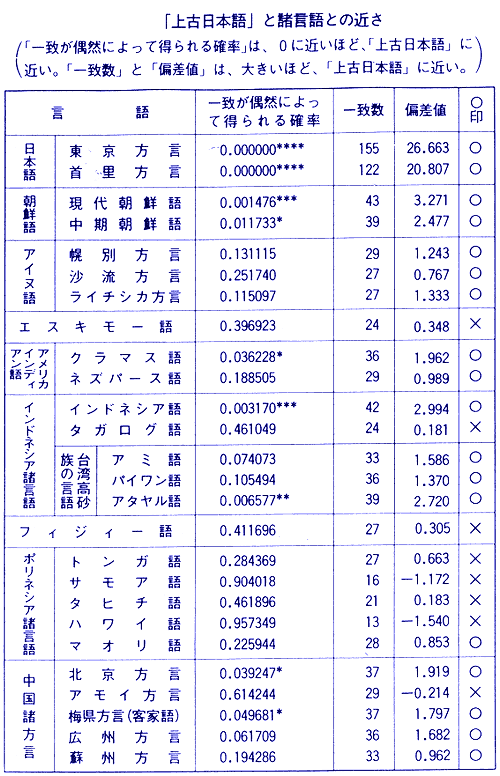
|
|
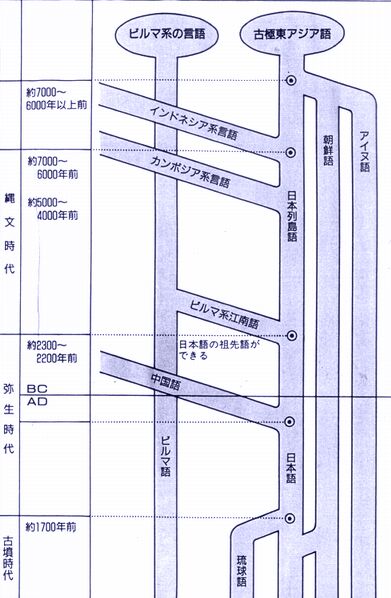
4.日本語の起源
|
|
語彙についてのこのような分析と、前回の、文法、音韻の分析などを総合すると、 日本語の成立シナリオは、おおよそ以下のように描ける。 |
|
|
TOP>活動記録>講演会>第193回 | 一覧 | 上へ | 次回 | 前回 | 戻る |